AWS Redshift là gì? 7 ưu điểm của AWS Redshift

Bạn đang sở hữu một lượng dữ liệu khổng lồ (Big Data) lên đến hàng ngàn Terabyte từ Website, App Mobile, Hệ thống bán hàng (ERP) và CRM? Bạn đang chật vật vì các câu lệnh SQL truy vấn báo cáo cuối tháng mất đến hàng chục giờ đồng hồ mới chạy xong trên các Database truyền thống (như MySQL hay SQL Server)?
Đó chính xác là lúc bạn cần đến Amazon Redshift. Hãy cùng CodeStar Academy giải mã AWS Redshift là gì, khám phá kiến trúc bên trong và 7 lý do khiến nó trở thành công cụ phân tích dữ liệu (Data Analytics) số 1 được các tập đoàn lớn tin dùng.
AWS Redshift là gì?
AWS Redshift là một dịch vụ Kho dữ liệu (Data Warehouse) trên nền tảng điện toán đám mây được quản lý toàn diện bởi Amazon Web Services (AWS).
Nhiệm vụ duy nhất và thiêng liêng nhất của Redshift là: Phân tích một lượng dữ liệu siêu khổng lồ (lên tới hàng Petabyte) với tốc độ chớp nhoáng.
Để dễ hình dung, chúng ta cần phân biệt hai khái niệm cốt lõi trong thế giới Database:
- OLTP (Online Transaction Processing – Xử lý giao dịch trực tuyến): Đây là các Database truyền thống (như Amazon RDS, MySQL, PostgreSQL). Chúng sinh ra để ghi lại các giao dịch nhỏ lẻ liên tục (Ví dụ: Thêm 1 đơn hàng mới, cập nhật tên User).
- OLAP (Online Analytical Processing – Xử lý phân tích trực tuyến): Đây chính là thế giới của AWS Redshift. Nó không giỏi việc ghi từng dòng dữ liệu lẻ tẻ, nhưng nó cực kỳ xuất sắc trong việc đọc hàng tỷ dòng dữ liệu cùng một lúc để tính toán tổng doanh thu, tìm ra xu hướng mua hàng của người dùng trong 5 năm qua chỉ trong vài giây.
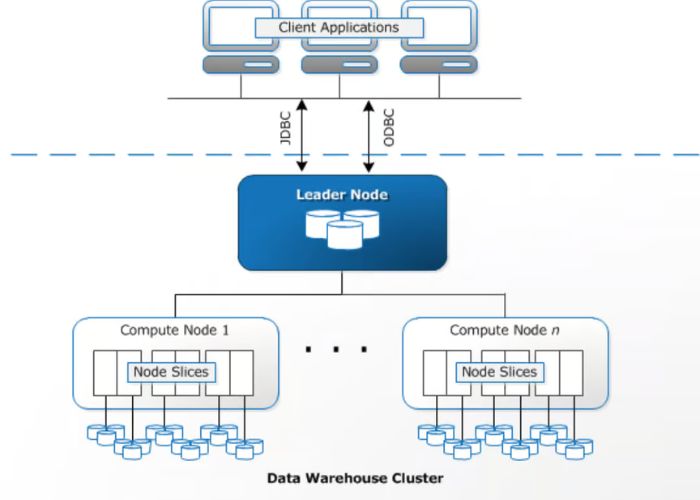
Khám phá kiến trúc bên trong AWS Redshift
Tại sao Redshift lại có thể xử lý hàng tỷ bản ghi nhanh đến vậy? Bí mật nằm ở kiến trúc lõi của nó:
Cluster: Trái tim của Redshift
Một hệ thống Redshift được gọi là một Cluster (Cụm máy chủ). Một Cluster bao gồm 1 Leader Node (Nút lãnh đạo) và nhiều Compute Node (Nút tính toán) hoạt động phối hợp với nhau.
Leader Node: Bộ não điều phối
Khi bạn gõ một câu lệnh SQL phức tạp (Ví dụ: Tính tổng doanh thu theo từng tháng của 10 triệu khách hàng), câu lệnh này sẽ được gửi đến Leader Node. Leader Node sẽ đóng vai trò như một vị tướng, phân tích câu lệnh SQL đó, lên kế hoạch tối ưu và chia nhỏ công việc ra giao cho các Compute Node cấp dưới.
Compute Node và sức mạnh xử lý song song (MPP)
Compute Node là những cỗ máy cày ải thực sự. Redshift sử dụng kiến trúc MPP (Massively Parallel Processing – Xử lý song song quy mô lớn).
Nếu bạn có 10 Compute Node, Leader Node sẽ chia khối dữ liệu 100GB thành 10 phần, mỗi Node xử lý 10GB cùng một lúc. Nhờ việc chia để trị này, tốc độ truy vấn tăng lên gấp hàng chục lần so với một máy chủ đơn lẻ.
Lưu trữ dạng cột (Columnar Storage)
Khác với MySQL lưu dữ liệu theo từng Hàng (Row), Redshift lưu dữ liệu theo từng Cột (Column).
Khi bạn chạy báo cáo chỉ cần lấy cột “Doanh thu” và cột “Tháng”, ổ cứng của Redshift chỉ việc đọc đúng 2 khối dữ liệu chứa 2 cột đó, bỏ qua hàng chục cột không cần thiết khác (như Tên, Địa chỉ, Số điện thoại). Kỹ thuật này giúp giảm thiểu tối đa thao tác đọc ổ cứng (Disk I/O), mang lại tốc độ “bàn thờ”.
7 Điểm nổi bật biến AWS Redshift thành lựa chọn hàng đầu cho doanh nghiệp

Lợi ích 1: Hiệu suất truy vấn cao gấp 10 lần
Nhờ sự kết hợp hoàn hảo giữa kiến trúc xử lý song song (MPP) và lưu trữ dạng cột (Columnar Storage), Redshift mang lại hiệu năng cao gấp 10 lần so với các kho dữ liệu truyền thống được lắp đặt tại công ty (On-premise).
Lợi ích 2: Khả năng mở rộng từ Gigabyte đến Petabyte không gián đoạn
Khi dữ liệu của công ty phình to, bạn chỉ cần vài cú click chuột trên AWS Console để thêm các Compute Node mới vào Cluster. Redshift sẽ tự động dàn đều dữ liệu ra các Node mới mà không làm gián đoạn các báo cáo đang chạy của bạn.
Lợi ích 3: Dịch vụ quản lý toàn phần (Fully Managed)
Hãy quên đi việc phải thức đêm cài đặt Server, vá lỗi phần mềm hay thiết lập Backup. AWS tự động sao lưu dữ liệu của bạn liên tục lên Amazon S3 và tự động phục hồi máy chủ nếu có sự cố phần cứng xảy ra. Đội ngũ Data Engineer chỉ cần tập trung vào việc viết câu lệnh SQL.
Lợi ích 4: Tích hợp hoàn hảo với hệ sinh thái AWS và công cụ BI
Dữ liệu thô từ Web/App sẽ được hút qua Amazon Kinesis, làm sạch bằng AWS Glue và đổ thẳng vào Redshift. Từ Redshift, bạn có thể dễ dàng kết nối với các công cụ Business Intelligence (BI) như Tableau, Power BI hay Amazon QuickSight để vẽ biểu đồ báo cáo tuyệt đẹp cho Ban giám đốc.
Lợi ích 5: Tối ưu chi phí đột phá với Redshift Serverless
Nếu công ty bạn chỉ chạy báo cáo vài lần trong ngày, việc thuê một Cluster Redshift chạy 24/7 sẽ rất lãng phí. AWS ra mắt Redshift Serverless để giải quyết việc này. Hệ thống sẽ tự động bật lên khi có người chạy câu lệnh SQL và tự động tắt đi khi không dùng. Bạn chỉ phải trả tiền cho số giây tính toán thực tế.
Lợi ích 6: Bảo mật đa lớp chuẩn quốc tế
Mọi dữ liệu nằm trong Redshift đều được mã hóa bằng phần cứng (KMS). Hệ thống được đặt gọn gàng trong Mạng riêng ảo (Amazon VPC) và quản lý quyền truy cập cực kỳ chi tiết đến từng cột dữ liệu thông qua AWS IAM.
Lợi ích 7: Đọc dữ liệu trực tiếp trên S3 với Redshift Spectrum
Nếu bạn có hàng ngàn file CSV, JSON dung lượng nhiều Exabyte nằm trên Amazon S3 (Data Lake), bạn không cần phải tốn công copy chúng vào Redshift. Tính năng Redshift Spectrum cho phép bạn gõ lệnh SQL truy vấn trực tiếp lên các file đó ngay trên S3, tạo ra một kiến trúc Lake House vô song.
Các ứng dụng thực tiễn của AWS Redshift
- Xây dựng hệ thống Business Intelligence (BI) nội bộ: Gom toàn bộ dữ liệu từ các phần mềm Kế toán, Bán hàng, Nhân sự về một nguồn duy nhất (Single Source of Truth) để làm báo cáo quản trị cấp cao.
- Phân tích hành vi khách hàng (Customer 360): Phân tích hàng tỷ log truy cập (Clickstream) trên Website để tìm ra những khách hàng có khả năng rời bỏ dịch vụ cao nhất (Churn rate).
- Chạy Machine Learning bằng SQL (Redshift ML): Cho phép các Data Analyst dùng chính câu lệnh SQL quen thuộc để tạo ra các mô hình Trí tuệ nhân tạo (AI) dự đoán doanh thu tháng tới mà không cần phải biết code Python phức tạp.
Lời kết
AWS Redshift không chỉ là một công cụ lưu trữ, nó là trái tim của mọi hệ thống phân tích dữ liệu khổng lồ (Big Data). Việc thấu hiểu AWS Redshift là gì và làm chủ được kiến trúc của nó sẽ giúp các Kỹ sư Dữ liệu (Data Engineer) biến những núi dữ liệu thô kệch thành những mỏ vàng tri thức, dẫn dắt các quyết định sống còn của doanh nghiệp.
Bạn đã sẵn sàng để trở thành Chuyên gia Hệ thống Dữ liệu trên nền tảng AWS?
Việc tự học các hệ thống Big Data khổng lồ này thường mất rất nhiều thời gian và rủi ro tốn kém chi phí nếu cấu hình sai. Hãy để CodeStar Academy thiết kế lộ trình ngắn nhất cho bạn!
Tham gia ngay Khóa học AWS Thực chiến dành cho người mới tại CodeStar:
- Đội ngũ giảng viên là các Chuyên gia Cloud Architect / Data Engineer thực chiến với >10 năm kinh nghiệm.
- Lộ trình học bài bản, tập trung hơn 70% thời lượng vào thực hành Lab trực tiếp trên môi trường AWS thật.
- Cầm tay chỉ việc tự xây dựng Data Lake, thiết lập AWS Glue, vận hành Amazon
Đừng chần chừ! Khám phá ngay Khóa học AWS tại CodeStar Academy hôm nay để nhận ưu đãi học phí tốt nhất và sẵn sàng bứt phá sự nghiệp Data Engineer của bạn!
